HTTP
http c'est quoi ?
http : est l'abréviation de HyperText Transfer Protocol. (est-ce plus clair ?)
En plus clair :
Protocole : c'est une règle.
Transfert : pour transférer (communiquer).
HyperTexte : c'est du texte qui contient des liens vers d'autres ressources (documents, images etc...)
http est donc le protocole qui permet à une machine (client) de demander et de recevoir une ressource d'un serveur.
Requête http
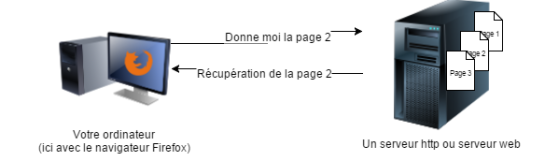
Lorsque l'on se connecte à un serveur pour lui demander une page cela se fait sous forme de requête.
Notre navigateur va envoyer une requête au serveur, pour lui demander une page et celui-ci enverra une réponse, après la lecture de la requête.
Pour simplifier, la demande se fait avec la méthode GET( Le verbe « to Get » en anglais se traduit par « obtenir », « avoir », « se procurer » )
La méthode Get va envoyer différentes informations au serveur pour que celui-ci puisse lui renvoyer le contenu demandé.
Voici les informations que la méthode Get envoie au serveur :
Évidemment : la page demandée (ou le contenu demandé) -> c'est à dire l'URL de la ressource,
le numéro de version du protocole http utilisé (souvent HTTP 1.1),
le langage utilisé,
le navigateur utilisé (Firefox, Chrome,... ) et sa version,
le type de document demandé (par exemple HTML),
les cookies,
la conservation de la connexion,
...
Exemple :
Allez sur la page : https://fr.wikipedia.org/wiki/Informatique
Dans la plupart des navigateurs lorsque l'on appuie sur F12 (et actualiser la page), cela affiche un panneau qui permet de voir dans l'onglet réseau les requêtes faites par le navigateur et la réponse du serveur.
On peut observer, les différentes requêtes effectuées par le navigateur :
Le code d'état à 200 signifie que la demande a bien été traitée (on peut avoir un code à 304 , si la ressource est déjà dans le cache du navigateur, et un code 404 si la ressource n'a pas été trouvée)
On peut également avoir un aperçu de la réponse faite par le serveur.
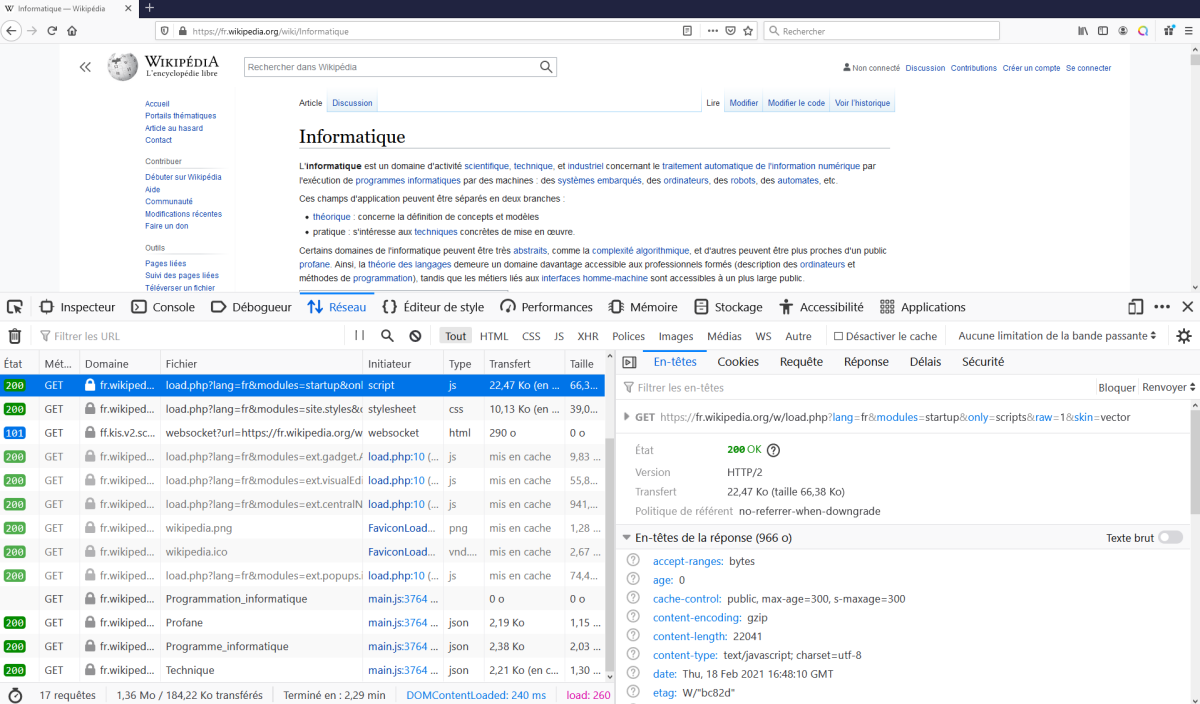
Dans cet onglet, on peut aussi voir les informations suivantes :
L'URL de la requête : https://fr.wikipedia.org/wiki/Informatique
Le type du document : HTML
La méthode de la requête : GET
La version : HTTP/.20
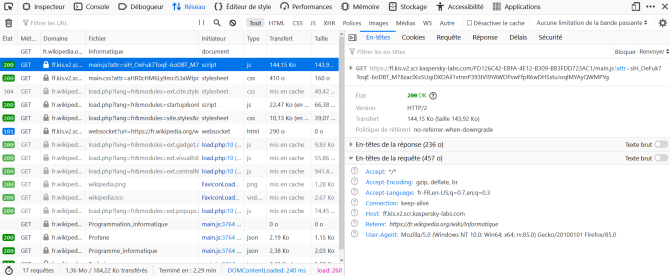
Exemple : La requête
Dans l'en-tête de la requête, nous pouvons voir entre autres les informations suivantes :
"text/html" : le client s'attend à recevoir du HTML
"FR" : en langue française
Gzip : type d'encodage
"Mozilla/5.0 : le navigateur web employé est Firefox de la société Mozilla
...
Exemple : La réponse
Une fois la requête reçue, le serveur va renvoyer une réponse, voici un exemple de réponse du serveur :
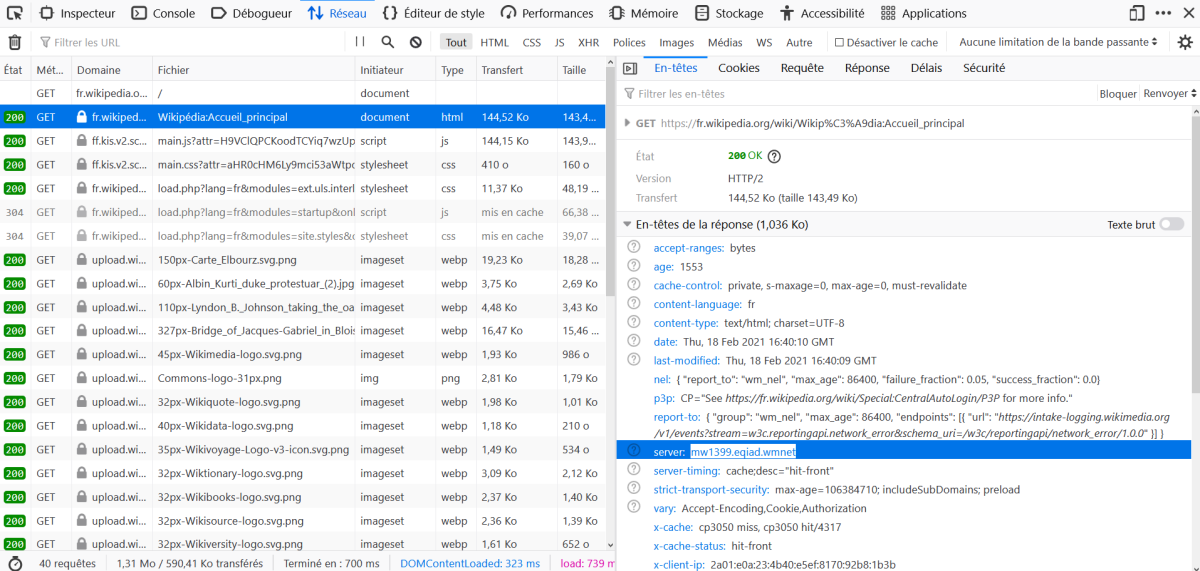
Nous n'allons pas détailler cette réponse, voici quelques explications sur les éléments qui nous seront indispensables par la suite :
Commençons par le type "text/html" : le serveur renvoie du code HTML, une fois ce code reçu par le client, il est interprété par le navigateur qui affiche le résultat à l'écran. Cette partie correspond au corps de la réponse.
Une ligne nous intéresse plus particulièrement :
Server: mw1269.epiad.wmnet
Le serveur web qui a fourni la réponse http ci-dessus a comme système d'exploitation une distribution GNU/Linux nommée "Debian" (pour en savoir plus sur GNU/Linux, n'hésitez pas à faire vos propres recherches).
"epiad" est le cœur du serveur web et puisque c'est ce logiciel qui va gérer les requêtes http (recevoir les requêtes http en provenance des clients et renvoyer les réponses http). Il existe d'autres logiciels capables de gérer les requêtes http (Apache, nginx, lighttpd...). Apache est le plus populaire puisqu'il est installé sur environ la moitié des serveurs web mondiaux !
Revenons sur la méthode employée
Une requête HTTP utilise une méthode (c'est une commande qui demande au serveur d'effectuer une certaine action). Voici la liste des méthodes disponibles :
GET, HEAD, POST, OPTIONS, CONNECT, TRACE, PUT, PATCH, DELETE
Détaillons 4 de ces méthodes :
GET (vu ci-dessus) : c'est la méthode la plus courante pour demander une ressource. Elle est sans effet sur la ressource.
POST : cette méthode est utilisée pour soumettre des données en vue d'un traitement (coté serveur). Typiquement c'est la méthode employée lorsque l'on envoie au serveur les données issues d'un formulaire (avec une balise form, on verra cela dans l'activité sur le HTML et le CSS).
DELETE : cette méthode permet de supprimer une ressource sur le serveur.
PUT : cette méthode permet de modifier une ressource sur le serveur.
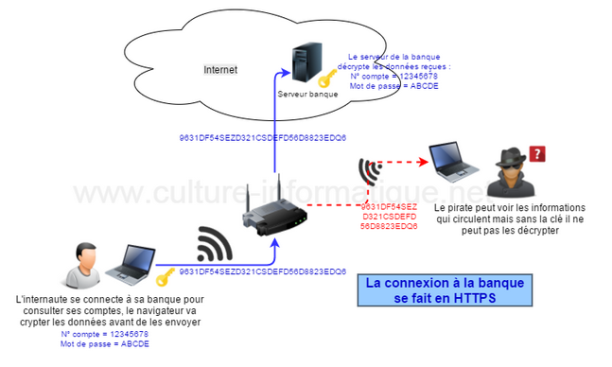
http vs https
La plupart du temps, on ne fait que recevoir des ressources d'un serveur, et ces informations sont transmises en clair...
Imaginons une communication avec sa banque en http..
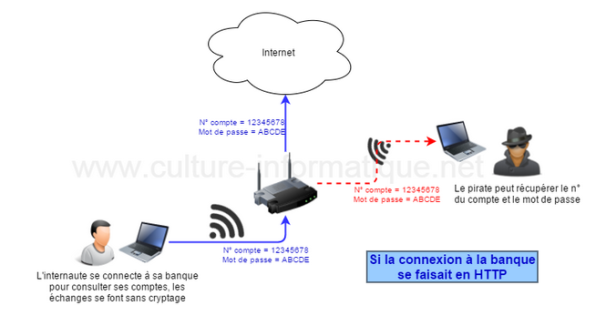
Si la connexion se fait en http, alors tous les échanges entre son ordinateur et sa banque se font en texte, non crypté et donc lisible par n'importe quelle personne qui espionne le réseau. (comme un pirate par exemple).
Pour pallier à ce problème de sécurité, il a fallu trouver une parade : c'est le https !
Le protocole https est composé de 2 protocoles :
le protocole http
le protocole ssl(Secure Socket Layer) : c'est lui qui donne le S au protocole httpS (S pour Secure)
Le serveur et le client vont établir une connexion chiffrée dont eux seuls pourront lire le contenu car seul le client et le serveur en possession de la clé de décryptage pourront déchiffrer les données reçues.